Attention 톺아보기
어텐션에 대해서 공부해보았다.
Attention is all you need 논문과 Understanding Deep Learning 책, 그리고 나동빈님의 유튜브 영상을 많이 참고했다.
1. Dot-product self-attention
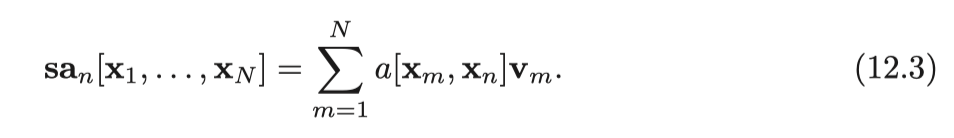

스칼라 가중치 a[X_M, X_N]은 n번째 출력이 입력 X_m에 기울이는 어텐션의 정도이다. 셀프 어텐션은 각 출력을 생성하기 위해 값을 서로 다른 비율로 라우팅한다.

입력된 Query와 Key에 대해서 dot-product로 유사도를 계산한다. 여기서 각각의 단어들이 서로 얼마나 유사한지 계산한 어텐션값이 나온다고 할 수 있다.
예를 들어 셀프 어텐션의 과정을 칵테일을 만드는 과정이라고 가정하자.
1단계: 유사도 계산 (Q · K) - “어떤 재료가 중요한가?” (레시피 초안 작성)
-
쿼리(Query): 내가 지금 만들고 싶은 칵테일의 ‘핵심 컨셉’이다. 예를 들어, “사과”라는 단어를 처리할 차례라면, 컨셉은 “사과”가 된다.
-
키(Key): 각 재료(단어)가 가진 ‘고유한 특징이나 맛’이다. “사과”, “바나나”, “자동차” 같은 재료들이 각자 자신의 특징(Key)을 가지고 있다.
-
내적(Q · K): 나의 컨셉(“사과”)과 각 재료의 특징(“사과”, “바나나”, “자동차”)이 얼마나 잘 맞는지 점수를 매기는 과정이다.
-
Q(“사과”) · K(“사과”) = 10점 (매우 유사함)
-
Q(“사과”) · K(“바나나”) = 3점 (좀 관련 있음, 둘 다 과일)
-
Q(“사과”) · K(“자동차”) = 0.1점 (거의 관련 없음)
-
2단계: 소프트맥스(Softmax) - “재료 비율 정하기” (레시피 완성)
위에서 얻은 중요도 점수 [10, 3, 0.1]은 그냥 점수일 뿐, 실제 비율로 사용하기는 어렵다. 소프트맥스는 이 점수들을 **총합이 1(100%)이 되는 ‘비율’**로 바꿔준다.
[10, 3, 0.1] → Softmax → [0.90, 0.09, 0.01]
이제 최종 레시피가 완성되었다.
사과 맛 칵테일을 만들려면, 사과 90%, 바나나 9%, 자동차 1% 비율로 섞으면 된다.
3단계: 값(value)과 곱하기 - ” 비율대로 실제 내용물을 섞기” (칵테일 제조)

값(Value): 각 재료(단어)가 가진 **‘실제 내용물’ ** 이다. 키(Key)가 재료의 ‘이름표’나 ‘맛의 특징’이라면, 값(Value)은 그 재료가 가진 ‘진짜 알맹이(의미, 정보)‘라고 할 수 있다.
이제 완성된 레시피(소프트맥스 값)에 따라 실제 내용물(Value)을 섞을 차례이다.
이때 연산은 ‘내적’이 아니라 ‘가중합(Weighted Sum)’ 즉, 각 단어의 Value 벡터에 해당 단어의 소프트맥스 비율을 곱한 뒤, 모두 더하는 것이다.
(사과의 Value 벡터 × 0.90)
(바나나의 Value 벡터 × 0.09)
(자동차의 Value 벡터 × 0.01)
= 최종 결과: “사과”의 새로운 벡터 표현
결론: 이 과정의 진짜 의미는?
“자기 자신을 포함한 문장 전체의 ‘의미(Value)‘를, 자기 자신과의 ‘관련도(Attention Score)‘에 따라 차등적으로 조합하여, ‘문맥이 완벽하게 반영된 새로운 나’를 만드는 과정” 이다.
초기의 “사과” 벡터는 그냥 ‘사과’라는 사전적 의미만 가진다.
하지만 어텐션 계산이 끝난 후의 “사과” 벡터는, **90%의 자기 자신(사과)의 의미와, 9%의 ‘과일’이라는 문맥을 제공한 바나나의 의미, 그리고 1%의 미미한 다른 의미들이 조합된, 문맥적으로 매우 풍부해진 ‘사과’**가 되는 것이다.
이것이 셀프 어텐션이 단어의 의미를 문맥에 따라 유연하게 파악할 수 있는 이유라고 할 수 있다.